解説
標準化とは、データを一定のルールに基づいて変形し、利用しやすくすることです。データの多くは、数値の単位が異なっていたり、あるいは数値の大小が極端に異なったりしています。そういったデータをそのまま扱ってしまうと、特定のデータの影響が強く出てしまい、関係性や予測などを行う調査で良い結果を得られないことがあります。そのため、データ処理対象となる各データの尺度を同じに揃える加工が必要になります。
主要な標準化の方法を以下の表にまとめます。
| 標準化 | 特徴 |
|---|---|
| min-max normalization | 最大値/最小値に影響されやすい |
| z-score normalization | 外れ値に強い |
min-max normalizationは、最小値0、最大値1の範囲でデータを正規化します。以下の算出式で導くことができます。
[math]\LARGE{x_{new}^i = \frac{x^i – x_{min}} {x_{max} – x_{min}}}[/math]
min-max normalizationは、標準化後のデータ算出に最小値・最大値を用いるため、最大値・最小値の影響を強く受けてしまいます。つまり、外れ値が混ざっているとその値に大きく引っ張られてしまう問題があります。
その問題を解消したのが、z-score normalizationとなります、
z-score normalizationは、データの加算平均が0、分散が1になるように各データを正規化します。以下の算出式で導く事が出来ます。
[math]\LARGE{x_{new}^i = \frac{x^i – \mu} {\sigma}}[/math]
このように、データxから平均を引き、その値を標準偏差で割ることで、外れ値の影響を小さくすることができます。
ステップアップ
min-max normalizationは、最大値と最小値を用いて算出するため、処理対象データの取りうる値の範囲が事前に分かる場合は、min-max normalizationによる標準化を選択することも検討しても良さそうです。
とはいえ、データの最大値・最小値が事前にわかっているケースは非常に少ないですし、外れ値の影響も考えると、基本はz-score normalizationを使うことで良いと思います。
キーワード
- 標準化
- 外れ値
- min-max normalization
- z-score normalization
ソースコード
zscore_normalization.py:z-score normalizationでデータを標準化するプログラム
# -*- coding: utf-8 -*-
import numpy as np
from scipy.stats import zscore
# テストデータを生成(外れ値:10000)
data = np.array([150, 20, 10000, 10, 300])
def z_score_normalize_data(data):
normalization_data=zscore(data)
# 結果を表示する
print(data)
print(normalization_data)
if __name__ == '__main__':
z_score_normalize_data(data)
このプログラムを実行すると、与えられたデータリストと、与えられたデータリストをz-score normalizationで標準化した結果が表示されます。
[ 150 20 10000 10 300] [-0.49223434 -0.52511741 1.99929095 -0.52764688 -0.45429233]
結果から得られたデータをもとに、実際に、どのように標準化がされているか、グラフを描画して確認してみます。
create_bar_graph_for_comparison.py:標準化前後のデータの棒グラフを描画するプログラム
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
y1 =np.array([ 150 , 20, 10000 , 10 , 30])
y2 =np.array([-0.49223434, -0.52511741 , 1.99929095, -0.52764688, -0.45429233])
x = np.array([1, 2, 3, 4, 5])
def create_bar_graph():
bar_width = 0.4
# 標準化前のデータを棒グラフで描画
plt.ylim([0,15000]) # y軸の範囲: 0<y<10
plt.bar(x, y1, color = "grey", width = bar_width, label = "row_data", align = "center")
plt.legend()
plt.xticks(x + bar_width / 2, ["data1", "data2", "data3", "data4", "data5", ])
plt.show()
# 標準化後のデータを棒グラフで描画
plt.ylim([-1,3]) # y軸の範囲を -1<y<3 に
plt.hlines(y=[0], xmin=0, xmax=6, linewidths=1)
plt.bar(x, y2, color = "grey", width = bar_width, label = "normal_data", align = "center")
plt.legend()
plt.xticks(x + bar_width / 2, ["data1", "data2", "data3", "data4", "data5", ])
plt.show()
if __name__ == '__main__':
create_bar_graph()
このプログラムを実行すると、標準化前のデータの棒グラフと、標準化後のデータの棒グラフを描画した画像が表示されます。
標準化後の棒グラフは、外れ値が平らに表現できていることが分かります。
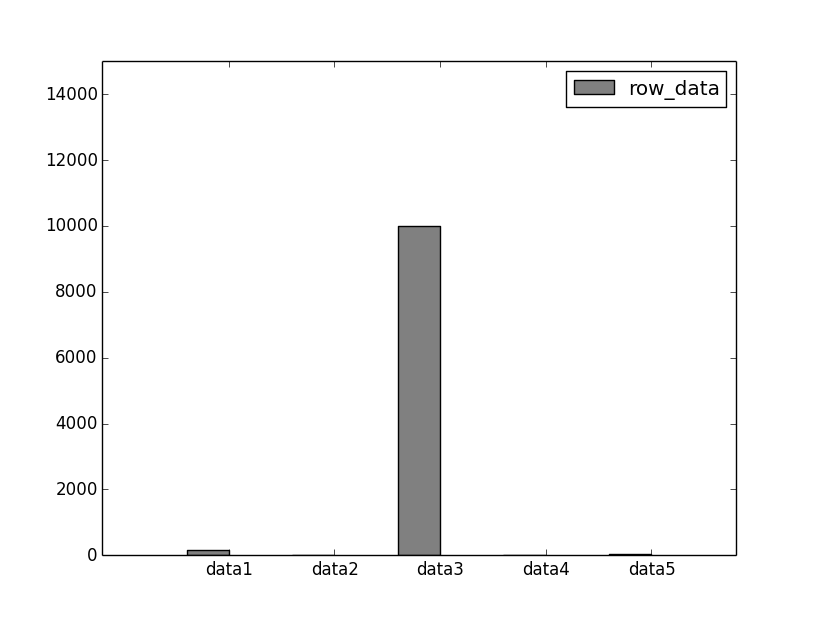
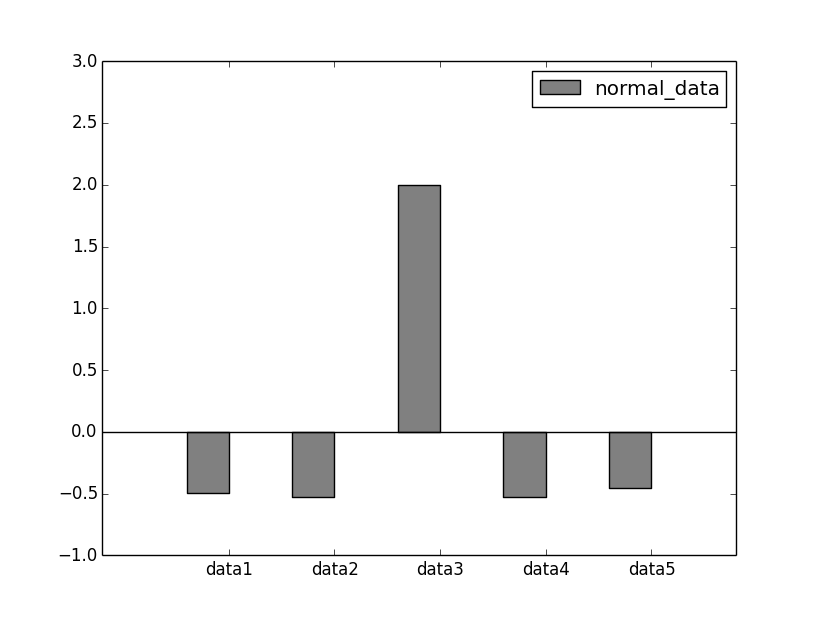
データセット
ー